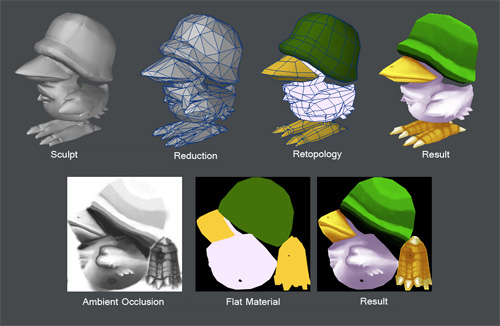
トゥーンシェーダを試してみました!
今回はトゥーンシェーダと平行して、影の色処理にHSV-RGB変換を
やっていたんですが、中身がよく分からない状態で使用している上に
シェーダ命令が限界突破してしまったので、少し頭を冷やして
色空間の変換式をちょっくら研究してみることにしました。
さっそくですが、以下に色空間の変換式をメモしておきます。
RGB to YUV
Y = 0.299 * R + 0.587 * G + 0.114 * B
U = -0.169 * R - 0.331 * G + 0.500 * B
V = 0.500 * R - 0.419 * G - 0.081 * B
YUV to RGB
R = 1.000 * Y + 1.402 * V
G = 1.000 * Y - 0.344 * U - 0.714 * V
B = 1.000 * Y + 1.772 * U
RGB to YCbCr
Y = 0.29900 * R + 0.58700 * G + 0.11400 * B
Cb = -0.16874 * R - 0.33126 * G + 0.50000 * B
Cr = 0.50000 * R - 0.41869 * G - 0.08131 * B
YCbCr to RGB
R = Y + 1.40200 * Cr
G = Y - 0.34414 * Cb - 0.71414 * Cr
B = Y + 1.77200 * Cb
RGB to YIQ
Y = 0.2990 * R + 0.5870 * G + 0.1140 * B
I = 0.5959 * R - 0.2750 * G + 0.3210 * B
Q = 0.2065 * R - 0.4969 * G - 0.2904 * B
YIQ to RGB
R = Y + 0.9489 * I + 0.6561 * Q
G = Y - 0.2645 * I - 0.6847 * Q
B = Y - 1.1270 * I + 1.8050 * Q
RGB to HSV
(H:0~360,S:0~1,V:0~1,R,G,B:0~1)
V = max( R, G, B )
diff = V - min( R, G, B )
S = diff / V
if(R == V): H = 60 * (B - G) / diff
if(G == V): H = 60 * (R - B) / diff + 120
if(B == V): H = 60 * (G - R) / diff + 240
HSV to RGB
H(i) = (H/60)mod6
f = H / 60 - H(i)
p = V * (1 - S)
q = V * (1 - f * S)
t = V * (1 - (1 - f) * S)
if(H(i) == 0): R = V, G = t, B = p
if(H(i) == 1): R = q, G = V, B = p
if(H(i) == 2): R = p, G = V, B = t
if(H(i) == 3): R = p, G = q, B = V
if(H(i) == 4): R = t, G = p, B = V
if(H(i) == 5): R = V, G = p, B = q
それにしても、HSVだけ変換が面倒くさいですね。。
シェーダでHSV-RGB変換をやってしまうとif文判定がかなりかさばって
しまうので、正直やめたほうがいいなと思いました(スキップ自体は
いいことなんですが、命令レジスタ自体が圧迫されるので)。
それと研究してみて、ふとHSV-RGB変換をやらなくても影の色処理が
できる方法を思いついたので、今度はそちらを試してみようかと思います。